










|
|
Research at Aware
Here is a recent presentation I gave on the possibility of the creation of an Artificial General Intelligence and its ramifications for humanity.
|
Biometric Perturbations for Classifier Enhancement
|
Eye Localization
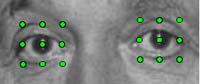
While many people would expect eye localization to have an impact on recognition accuracy, we showed that it had a significant quantitative impact. Even with ideal data, it is shown to have a significant effect on the recognition accuracy of several different face recognition algorithms. The response of various face recognition algorithms to eye perturbations was found to be similar, despite significant differences in algorithm design, suggesting that our observations are relevant to many face analysis systems. Interestingly, we found a significant difference between the effect of eye separation errors and the effect of eye location errors on recognition accuracy. The effect of eye localization appears to be more dramatic when errors are made in eye separation distance versus errors made in identifying the actual locations of eyes. Our results suggest that reliance on eye separation for scaling and normalization may be precarious especially in instances where face images are degraded or taken in more realistic environments. Since much of later face processing relies on proper scaling, our results indicate the need for additional "backup" methods of scaling, which may either complement the use of eye separation or supercede it. Our results also indicate that blurring/noise from a real imaging system may in fact help to make algorithms less sensitive to errors in eye location. The working hypothesis is that blurring seems to mitigate the effect of eye localization, making algorithms more stable with respect to eye perturbations: blurring may impact eye localization, but image smoothing mitigates the impact of such errors. Experiment results are available in our paper The Eyes Have It
|
CAPTCHAs
|
The Collective Learning Genetic Algorithm (CLGA)
The CLGA employs genotypic learning to do intelligent recombination based on a cooperative exchange of knowledge between interacting chromosomes. A CLGA consists of a population of adaptive learning agents each of which consists of two components: an adaptive learning automaton and a chromosome string representing the best solution the agent has found so far. Each agent in the population observes a unique set of features in the chromosomes of the other agents it interacts with in order to explicitly estimate the average observed fitnesses of k-order permutations of bits (where k is some small number) in the population, and to use that information to guide recombination. Agents collaborate and exchange knowledge instead of symbols, which they use to modify their own chromosome strings in a Lamarckian fashion, essentially replacing the random crossover operator with a consensus of information based on the permutations of observed symbols that yield the best string fitness. As in standard genetic algorithms, the stages of evolution are still controlled by a global algorithm, but most of the control in the CLGA is distributed among agents that are individually responsible for recombination and selection of surviving offspring. Note that no random mutation is used. The earliest incarnation of the CLGA did use random mutation [Riopka and Bock, 2000], but later experiments showed that random mutation actually degrades performance, interfering with the actual mechanism of CLGA recombination. There is strong evidence to suggest that the success of the CLGA is not due to a capacity to do linkage learning (as was first thought), but due to the CLGA's high resistance to convergence and its ability to modify its recombinative behavior based on the consistency of the information in its environment, specifically, the observed fitness landscape. Contrary to other self-adaptive algorithms that seek to explicitly alter algorithm behavior as evolution proceeds, the CLGA seems to adapt its behavior naturally, as a consequence of the mechanism used to do recombination. See my paper Adapting to Complexity During Search in Combinatorial Landscapes on this topic. Click here to see a screen capture of the algorithm in progress.
What Inspired the CLGA?Although I refer to the CLGA as a geneticalgorithm, it could also be called a cultural algorithm, because the primary mechanism of the CLGA was actually inspired by human behavior. In a course on cognition, I developed, with a colleague, a human simulation of a genetic algorithm to accomplish several things: 1. to obtain experience designing and performing a pilot experiment for human factor experiments, 2. to design an interactive method of teaching students about genetic algorithms, and lastly (quite ambitiously) 3. to determine how types of information exchange and the type of data exchanged between chromosomes (in this case humans) affected the efficiency of the genetic algorithm. Obviously, the small number of trials we could run (involving about 10 populations of 10 students - paid handsomely with pizza and the promise of honourable mention in future papers) limited the meaningfulness of the results. Nevertheless, a *very* interesting phenomenon occurred during the human simulations. Conversations recorded during the experiments showed a significant flow of information between the "human chromosomes" which encouraged them to collaborate in order to make their hypothesis testing more efficient! Combine this idea with collective learning systems (which was originally designed with the emulation of human behavior in mind) and voila...the CLGA was born. One and a half years of painstaking programming later, I finally had a prototype CLGA that did some very facinating things! An even more amazing fact is that the same machine learning paradigm used in the CLGA is also capable of performing a variety of image analysis and pattern recognition tasks from a relatively new and fresh perspective.
Why Should Anyone Be Interested in the CLGA?For one thing, the concept behind the CLGA is unique in that it relies on adaptive learning automatons to learn from one another to accumulate information about the fitness landscape. That information is then used to guide the search strategy, enabling the CLGA to essentially adapt to problem complexity as seen by the CLGA. Second, the CLGA is highly resistent to convergence because the algorithm does not rely explicitly on schemata to modify its strings (only on the knowledge acquired about them) and hence the diversity of the population schemata does not directly affect the exploratory capabilities of the CLGA. Third, the agent-oriented approach to genetic computation has the potential for a vast number of enhancements to the intelligence of search algorithms in general. The CLGA's capacity to simultaneously search for good and bad solutions, yet still work cooperatively is only one very interesting example. Finally, the CLGA really does behave in interesting new ways, providing fertile ground for future researchers to explore and understand. If you are interested in finding out more about it, or would like some code to test, please don't hesitate to contact me. |
Hubble Telemetry Analysis (HTA) Project
The approach presented here, uses a collective learning paradigm (in a modified ALISA engine) to essentially generate multi-dimensional non-parametric pdfs based on past telemetry data, and to use that information to detect anomalous sensor input. The approach is especially powerful because it is adaptive, can be easily modified to handle any number of input sensors (whether from HST or any other multi-sensor system) and its sensitivity can be easily adjusted for Type II errors. It is also immune to the brittleness of a typical rule-based system. The figure below (click on the image to obtain a higher resolution image [225K]) depicts a set of HST orbits and graphical output of the HTA program. The output is a "test" result after training on approximately five days of archived telemetry data (187 electrical sub-system related sensors) resulting in the detection of a (known) anomaly in the electrical sub-system of the HST. Red areas show anomalous regions, and the lighter the region, the more "normal" it is, as compared to the data on which it was trained.
|
|
|
Automatic Metaphase Finder
|
|
|
Fourier Domain Chromosome Eigenanalysis
The objective of eigenanalysis is to reduce a large number of original, highly correlated variables to a small number of transformed, independent variables. For an image of a chromosome, this kind of approach is feasible, because most of the crucial banding information is along the length of the chromosome arms. As a result, eigenanalysis can either be done on an individual chromosome (single chromosome eigenanalysis) where the vectors of the data matrix are the columns of a single chromosome image, or on a set of chromosomes (homolog chromosome eigenanalysis) where the vectors of the data matrix are whole chromosomes (column concatenated). The first step in applying Fourier domain eigenanalysis is to take the fourier transform of the data matrix in the dimension corresponding to the length of the chromosome. To achieve proper band alignment, eigenanalysis in the Fourier domain must be performed in two distinct phases. First, eigenanalysis is performed on the magnitude portion of the Fourier expansion and the magnitude data matrix reconstructed using only the k most significant eigenvectors (where k is determined by the desired reconstruction accuracy). Second, eigenanalysis is performed on the dot product of the reconstructed magnitude matrix and the phase portion of the original Fourier expansion, and similarly reconstructed using only the k most significant eigenvectors (where k is determined by the desired reconstruction accuracy). The result is then divided by the reconstructed magnitude matrix to obtain the final reconstructed phase matrix. Inverse fourier transforming gives the desired reconstructed chromosome image(s). Thus, the spectrum is reconstituted using only significant phase components, and then inverse transformed to yield an image in which the bands are in registration from one chromosome to the next. Since positional information regarding the sinusoidal components of an image is encoded in the phase spectrum, synchronizing the phase spectra of the images in the set consolidates their banding patterns spatially while leaving amplitude information unchanged. The thumbnail images below show three examples of how eigenanalysis can be used: to generate prototype chromosomes[45K], to generate a "clean" karyotype from multiple karyotypes of the same person [31K], and for classification [48K}. Much of this work was done in collaboration with Ken Castleman (a very smart, great guy and co-founder of Perceptive Systems Inc., later Perceptive Scientific Instruments, Inc.) |
|
|
|
|
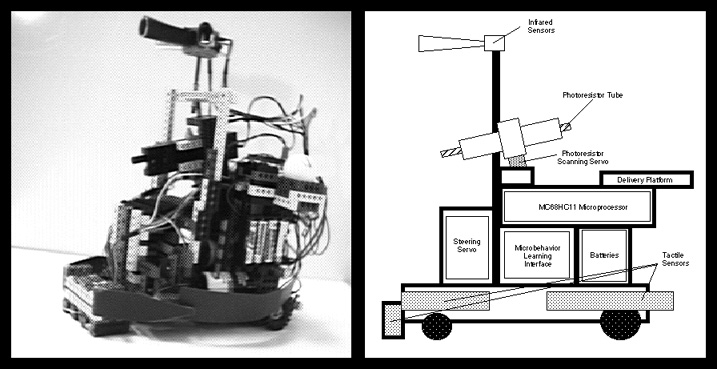
A Control Architecture for Autonomous Robots
|
|
|
Active Contours (Snakes)
Many different implementations of active contours have been described in the literature. The algorithm I developed for PSII implements a greedy algorithm based on [Williams and Shah, "A Fast Algorithm for Active Contours", CVGIP:Image Understanding, 55(1):14-26, 1992]. Its main advantages are computational efficiency and algorithmic simplicity. Its main disadvantage is the standard characteristic of any greedy algorithm - the extremely local nature of its decision criteria. Nevertheless, the algorithm was relatively simple to implement and apparently results in performance comparable to other more global approaches (see the Williams and Shah article). The general idea behind the algorithm is as follows. The algorithm begins with some starting contour. The energy of the first point on the contour is calculated and compared with the energies calculated for points in its immediate neighborhood. The new location of the contour point corresponds to the location of the point with the lowest energy. If that location is different from the current location of the contour point, the point is considered "adjusted". Performing this operation on all points of the contour once constitutes one iteration of the snake algorithm. This is repeated until an iteration causes no more points to be adjusted. At that point, the snake is said to have converged. I give a more thorough description of this implementation in [Castleman, Riopka and Wu, 1996] (see publications). In the image above (click on the image to obtain a higher resolution image [40K]), a Hough transform is used to obtain good initial guesses for the starting contour, and then the snake algorithm takes over. What was interesting about this algorithm was that the termination criteria had to include monitoring the algorithm for loops in the contour adjustment, since occasionally, the point adjustment would never stop, but simply cycle indefinitely with some (usually small) period. For this algorithm, loops were relatively easy to identify because I knew where to look. How would an artificial intelligence recognize loops in its own processing?.... |
Particle Tracking
The system on which this was implemented was meant to replace an analogue image analysis system (OMNICON) originally developed by Baush and Lomb which we used extensively in the lab for cell counting. You can imagine the fun I had with a digital image analysis system after working with an analogue one...to have access to the pixels of an image!...what a rush...The system also had an ALU for hardware convolving...I was in heaven...and of course, I've never looked back. No matter how much work I do in machine learning, image analysis will forever be my calling. ANYWAY...the images below show the particle tracker at work. The algorithm used the a prioriknowledge of particles descending downward to limit the search to a cone. Images were digitized from negatives obtained by taking long exposure photographs of strobed particles in a specially designed sedimentation chamber containing liquids of varying surface tension. Sedimentation rates were computed, particle sizes measured and in conjunction with interpolated particle/volume coefficient tables, used to estimate particle agglomeration. Yes...and all of this for a measly master's degree in mechanical engineering!....and I won't even mention the shear modulus experiments...sheesh.
|
|
|
|












{kind=link}